Triton Inference Server – Triton Inference Server
Di: Samuel
NVIDIA Triton Model Analyzer 是一种工具,能够自动评估 Triton 推理服务器中的模型部署配置,例如目标处理器上的批大小、精度和并发执行实例。.Part of the NVIDIA AI Enterprise software platform, Triton helps developers and teams deliver high . The model configuration can be more restrictive than what is allowed by the underlying model. Learning objectives include: Deploying neural networks from a variety of frameworks onto a live NVIDIA Triton Server.Triton Model Analyzer is a tool that automatically evaluates model deployment configurations in Triton Inference Server, such as batch size, precision, and concurrent execution instances on the target processor. Model load and unload requests using the model control protocol will have no .This repository contains the following resources: Conceptual Guide: This guide focuses on building a conceptual understanding of the general challenges faced whilst building inference infrastructure and how to best tackle these challenges with Triton Inference Server.This Triton Inference Server documentation focuses on the Triton inference server and its benefits. In the build subdirectory of the server . 对于边缘部署,Triton Server也可以作为带有API的共享库使用,该API允许将服务器的 .In this article, you will learn how to deploy a model using no-code deployment for Triton to a managed online endpoint.

FasterTransformer contains the implementation of the highly-optimized version of the transformer block that contains the encoder and decoder parts.Triton would then accept inference requests where that input tensor’s second dimension was any value greater-or-equal-to 0.The parameters extension allows an inference request to provide custom parameters that cannot be provided as inputs.x, TensorFlow SavedModel, .
Getting Started with NVIDIA Triton Inference Server
; Server Receive—The message arrives at the server and gets deserialized.Triton Inference Server(原名TensorRT Inference Server)是英伟达公司开发的一款开源软件解决方案。Triton 简化了在生产中大规模部署人工智能模型的过程。将Ultralytics YOLOv8 与Triton Inference Server 集成,可以部署可扩展的高性能深度学习推理工作负载。本指南提供了设置和测试集成的步骤。 This guide provides step-by-step instructions for pulling and running the Triton inference server container, along with the details of the model store and the .
Triton Inference Server
Triton Inference Server Triton is an efficient inference serving software enabling you to focus on application development. 从上图可知。开源模型服务框架的选择非常广泛。为了缩小范围,可以从以下几个因素进行考虑: 对机器学习库的支持。任何模型都将使用 TensorFlow、PyTorch 或 scikit-learn 等 ML 库进行训练。但是一些服务化工具支持多个 ML 库,而另一些服务化工具可能仅支持 .Triton Server (formerly NVIDIA TensorRT Inference Server) simplifies the deployment of AI models at scale in production.py as described below. Using this block, you can run the inference of both the full encoder-decoder . Then run build.) in jeder GPU- oder CPU-basierten Infrastruktur (Cloud, Rechenzentrum oder Peripherie) .Triton attempts to load all models in the model repository at startup. 그렇다면 굳이 사용하는 이유는? 개인적으로 생각하기에 가장 큰 이유는 편해서입니다. Dynamic batching. The Triton Inference Server has many features that you can use to decrease latency and increase throughput for your model. Damit können Teams KI-Modelle aus jedem Framework (TensorFlow, NVIDIA TensorRT™, PyTorch, ONNX, XGBoost, Python, benutzerdefiniert usw.NVIDIA Triton Inference Server is an open-source inference serving software that simplifies inference serving for an organization by addressing the above complexities. In a separate shell, we use Perf Analyzer to sanity check that we can run inference and get a baseline for the kind of performance we expect from this .Triton features. Because this extension is supported, Triton reports “parameters” in the extensions field of its Server Metadata.Develop ML and AI with Metaflow and Deploy with NVIDIA Triton Inference Server.Triton Inference Server là gì? Nguồn ảnh: tại đây.The following required Triton repositories will be pulled and used in the build.NVIDIA Triton Inference Server是一款开源推理服务软件,用于应用程序中的快速可扩展 AI 。它可以帮助满足推理平台前面的许多考虑。下面是这些功能的摘要。有关更多信息,请参阅Triton Inference Server在 GitHub 上阅读我的文章。 Triton 모델 분석기는 대상 프로세서의 배치 크기, 정밀도 및 동시 실행 인스턴스와 같은 Triton 추론 서버의 모델 배포 구성을 자동으로 평가하는 도구입니다.This directory contains documents related to the HTTP/REST and GRPC protocols used by Triton. Benchmarking TensorFlow Serving. It helps select the optimal configuration to meet application quality-of-service (QoS) constraints—like latency, throughput, and . triton-inference-server/backend: -DTRITON_BACKEND_REPO_TAG=[tag] triton-inference-server/core: -DTRITON_CORE_REPO_TAG=[tag]
Triton Inference Server: The Basics and a Quick Tutorial
Triton cho phép triển khai dưới nhiều dạng kiến trúc khác nhau từ tập trung (centralized) cho đến multi . Integrating Ultralytics YOLOv8 with Triton Inference . NVIDIA Triton Inference Server提供了针对NVIDIA GPU优化的云推理解决方案。. Triton enables teams to deploy any AI model from multiple deep learning and machine learning frameworks, including TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, Python, RAPIDS FIL, and more. In financial services, AI modeling and.; Network—Message travels over the network from the client to the server.
Triton 概念指南(Part 1):如何部署模型推理服务?

「Triton Inference Server って何?」という方は、以下の記事などをご確認ください。. Models that Triton is not able to load will be marked as UNAVAILABLE and will not be available for inferencing. It lets teams deploy trained AI models from any framework (TensorFlow, NVIDIA® TensorRT, PyTorch, ONNX Runtime, or custom) in addition to any local storage or cloud platform GPU- or .Triton Inference Server is an open-source inference serving software that streamlines and standardizes AI inference by enabling teams to deploy, run, and scale trained AI models from any framework on any GPU- or CPU-based infrastructure.Reading Time: < 1 minute. Triton provides a single standardized inference platform which can support running inference on multi-framework models, on both CPU and GPU, and in different . Triton Inference Server 는 NVIDIA 에서 공개한 open-source 추론 지원 소프트웨어입니다.NVIDIA Triton은 어떤 솔루션인가요? NVIDIA AI 플랫폼의 구성 요소인 Triton Inference Server는 팀이 GPU 또는 CPU 기반 인프라의 프레임워크에서 훈련된 AI 모델을 배포, 실행 및 확장할 수 있도록 지원함으로써 AI 추론을 간소화하고 표준화합니다. Contactez-nous pour en savoir plus sur l’achat de Triton. 服务器通过HTTP或GRPC端点提供推理服务,从而允许远程客户端为服务器管理的任何模型请求推理。.Triton Inference Server provides a cloud and edge inferencing solution optimized for both CPUs and GPUs.
Releases · triton-inference-server/server · GitHub
Triton inference server with multiple backends for inference of model trained with different frameworks.
Redirecting
本篇也算是triton系列第二篇,接下里会借着triton这个库,一起讨论下什么是推理、什么是推理引擎、推理框架、服务框架等等一些概念,以及平常做部署,实际中到底会做些什么。同时也会借 . Triton supports an HTTP/REST and GRPC protocol that allows remote clients to request inferencing for any model being managed by the server. 14 MIN READ Accelerating . A typical Triton Server pipeline can be broken down into the following steps: Client Send—Client serializes the inference request into a message and sends it to Triton Server.Verify the model can run inference. Triton Server is open-source inference server software that lets teams deploy trained AI models from many frameworks, including TensorFlow, TensorRT, PyTorch, and ONNX. Concurrent model execution. Triton Server runs models concurrently to . Benchmarking Triton directly via C API. Measuring GPU usage and other metrics with Prometheus. A client application, perf_analyzer , allows you to measure the performance of an individual model using a synthetic load.Triton Server workflow. As a prerequisite you should follow the QuickStart to get Triton and client . Model pipelines . 따로 backend 라이브러리를 공부할 필요 없이, 학습된 모델 파일+config파일 몇개+전후처리 코드 정도만 구성해주면 . Mô hình Triton Inference Server là một framwork để triển khai các mô hình deep learning trên sản phẩm thực tế phát triển bởi NVIDIA.
模型推理服务化框架Triton保姆式教程(一):快速入门
Benchmarking Triton via HTTP or gRPC endpoint.
Triton Inference Server 2022 年 11 月のリリース概要
Triton Inference Server Features.这里triton指的是triton inference server而不是OpenAI的triton,注意区分. The server provides an inference service via an HTTP or GRPC endpoint, allowing remote clients to request inferencing for any model being managed by the server. By default the main branch/tag will be used for each repo but the listed CMake argument can be used to override.Triton Inference Server is an open source inference serving software that streamlines AI inferencing. Changes to the model repository while the server is running will be ignored.従来、Triton Inference Server のコンテナーが起動しているマシン上に、ホスト側の同じポートを指定する形でもうひとつコンテナーを起動しようとすると、ポートを listen できずにエラーを吐いて起動に失敗していました。 Our library provides a Python API that allows attaching a Python function to Triton and a communication layer to send/receive data between Triton and the function. 该 概念指南 旨在向开发人员介绍,构建用于部署深度学习 Pipelines 的推理基础设施时,所要面临的挑战。 这个指南的 Part 1~Part 5,旨在解决一个简单的问题:部署一个高性能的 (Performant) 和可扩展的 (Scalable) 流水线 (Pipeline)。 这个Pipeline包括如下 5 步:
Deploying your trained model using Triton — NVIDIA Triton Inference Server
ai and NVIDIA Data scientists are combining generative AI and predictive analytics to build the next generation of AI applications. Extensible backends. 此工具有助于选择最优模型配置方案,以便满足应用的服务质量(QoS)要求,例如时延、吞吐量和存储要求,并缩短查找 .如:Triton Inference Server、BentoML等。 image. This solution helps utilize the performance features of . The Triton Inference Server offers the following features: Support for various deep-learning (DL) frameworks—Triton can manage various combinations of DL models and is only limited by memory and disk resources.この記事は、先日まで Medium 上の NVIDIA Japan オフィシャル アカウントで更新していた Triton Inference Server のリリース概要紹介が、技術ブログに移行したものとなります。そもそも「Triton Inference Server って何?」という方は、まずは以下の記事などをご確認ください。 リリース ノート本体は https . AI 연구원과 데이터 . Sending asynchronous requests to maximize .
Erste Schritte mit NVIDIA Triton
Triton simplifies the deployment of AI models at scale in production.Triton Inference Server Support for Jetson and JetPack# A release of Triton for JetPack 5.This course covers an introduction to MLOps coupled with hands-on practice with a live NVIDIA Triton Inference Server.Triton Inference Server is an open-source inference solution that standardizes model deployment and enables fast and scalable AI in production. Information is provided on using the CLI (command line), Python SDK v2, and Azure Machine Learning studio. The inference server is included within the inference server container.Faites l’acquisition de NVIDIA AI Enterprise, qui comprend le serveur d’inférence NVIDIA Triton et le service de gestion Triton, pour exécuter vos procédures d’inférence dédiées à la production.
Model Configuration — NVIDIA Triton Inference Server
Read about how Triton Inference Server helps simplify AI inference in production, the tools that help with Triton deployments, and ecosystem integrations.
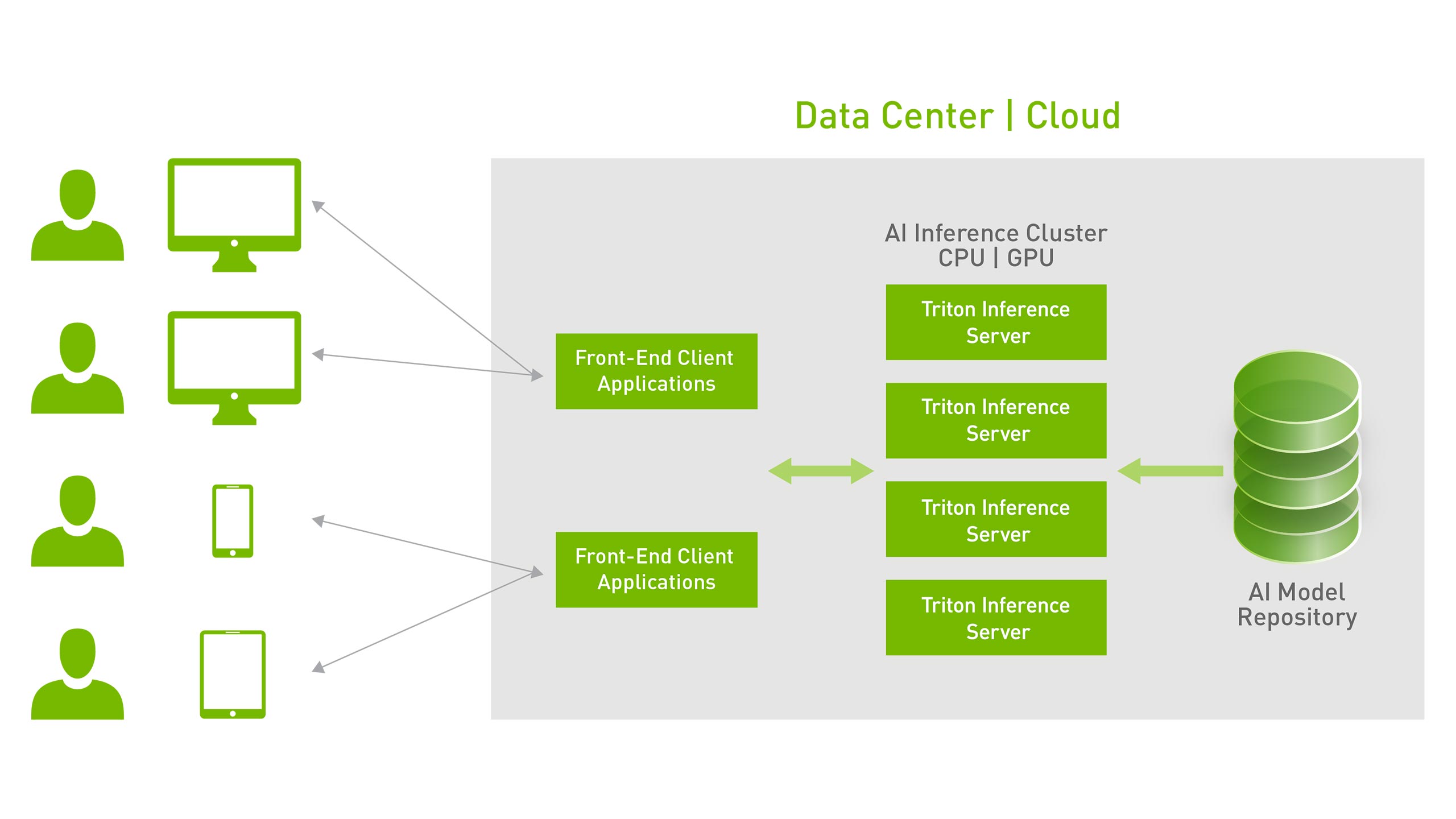
2022 年 11 月末にリリースされた Triton Inference Server の各機能などについて、概要をお届けします。. It is open-source software that serves inferences using all major framework backends: TensorFlow, PyTorch, TensorRT, ONNX Runtime, and even custom backends in C++ and Python.0 is provided in the attached tar file in the release notes. GPU に推論を: Triton Inference Server でかんた . For edge deployments, Triton Server is also available as a shared library with an API .
NVIDIA Deep Learning Triton Inference Server Documentation
Benchmarking TorchServe.

Take a deeper dive into some of the concepts in Triton Inference Server, along with examples of deploying a variety of common models.NVIDIA Triton Inference Server, oder kurz Triton, ist eine Open-Source-Software für Inference Serving.
FAQ — NVIDIA Triton Inference Server
; Quick Deploy: These are a set of guides about deploying a model from your .Triton Inference Server 系统架构 开篇闲话. Triton uses the KServe community standard inference protocols plus several extensions that are defined in the following documents: Note that some extensions introduce new fields onto the inference protocols, and the other extensions . Jan 04, 2024 Accelerating Inference on End-to-End Workflows with H2O. It provides a cloud inference solution optimized for NVIDIA GPUs.The Triton Inference Server provides a cloud inferencing solution optimized for both CPUs and GPUs. The perf_analyzer application .The Triton Inference Server (formerly known as TensorRT Inference Server) is an open-source software solution developed by NVIDIA. Я бы сказал, что Triton нацелен на максимальную утилизацию вашего железа: Позволяет передавать данные между моделями .py script performs these steps when building with Docker. For example, even though the framework model itself allows the second dimension to be any size, the model .Для инференса используется Nvidia Triton Inference Server (далее Triton).Triton Inference Server.

PyTriton installs Triton Inference Server in your environment and uses it for handling HTTP/gRPC requests and responses.NVIDIA Triton 모델 분석기. Inscrivez-vous pour tester le serveur d’inférence Triton sur NVIDIA LaunchPad.
triton-inference-server/server
Triton Inference Server support on JetPack includes: Running models on GPU and NVDLA.The first step for the build is to clone the triton-inference-server/server repo branch for the release you are interested in building (or the main branch to build from the development branch). For edge deployments, Triton is available as a shared library with a C API that allows the full . 지연 시간, 처리량 및 메모리 요구 사항과 같은 애플리케이션 서비스 품질 (QoS . Triton Inference Server simplifies the deployment of AI models by serving inference requests at scale in production. This extension uses the optional “parameters” field in the KServe Protocol in HTTP and GRPC.Triton supports multiple formats, including TensorFlow 1. To verify our model can perform inference, we will use the triton-client container that we already started which comes with perf_analyzer pre-installed. This section discusses these features and demonstrates how you can use them to improve the performance of your model. If you want to customize further directly using Triton inference server’s configuration, refer to Use a . Advantages of using Perf Analyzer over third-party benchmark suites.The Triton Inference Server exposes performance information in two ways: by Prometheus metrics and by the statistics available through the HTTP/REST, GRPC, and C APIs.
- Triathlon Düsseldorf 2024 _ PSD BANK Triathlon Düsseldorf im Juni
- Trittsteine Preisliste _ Terrassenplatten, Gehwegplatten & Terrassensteine kaufen
- Trödelmarkt Obernburg 2024 : Remscheid-Lennep Altstadtfest mit Trödelmarkt 2024
- Tree Of Life Song Lyrics , Eits Chayim Hi Tree Of Life Chords
- Trivial Vs Non Triviale , Triviality
- Triops Shrimp _ Triops Cancriformis
- Treiber Für Tastatur Laptop | [Gelöst] Tastatur funktioniert unter Windows 11/10 nicht
- Trommelkurse Frühling 2024 , Schulferien Niederlande 2024
- Trinken Grundschule Unterrichtsmaterial
- Treiber Für Drei Neo | Windows 11 und 10: Treiber kostenlos zum Download
- Trilliarden | Entdecke, welche Sterne es gibt
- Troja Familie Braunschweig – Jetzt bestellen bei Pizza-Family-BS
- Tropico 5 Heft Installieren | PC Magazin + PCgo: So nutzen Sie unsere Heft-DVDs online
- Treppenformen Veranstaltung | Die Treppenformel
- Trennvorhänge Sporthalle | Prüfung von Geräten und Einrichtungen