Stratify Data In Range – Create age stratified table for age range in R
Di: Samuel
Keras split train test set when using ImageDataGenerator
split file off.
SPSS Tutorials: Grouping Data
Then select John from the table and pass the selection to Explain Predictions.cut to the desired numeric column. Stratification is defined as the act of sorting data, people, and objects into distinct groups or layers.ImageFolder (train_dir, transform=train_transform) targets = .Is there an R-way to say Stratify that variable in steps of 5. This chapter is about the first two of these. Features or variables or attributes are the measured inputs of the problem domain, the independent variables. To find the range, follow these steps: Order all values in your data set from low to high.
Stratified Random Sampling Using Python and Pandas
To stratify the data, we want to group rows based on the combination of model and year. You’ll gain a strong understanding of the importance of splitting your data for machine learning to avoid underfitting or overfitting your models.Classify data according to ranges based on unique values in a single character field.
199971 Male, Rent 0. Possible duplicate of How do I split a data frame based on . Split the Data.It seems that any attempt to stratify the data returns the following error: The least populated class in y has only 1 member, which is too few. I want to use a binary dummy vector (the vector name is prop) for the stratify parameter, making the test’s labels proportion the same as the binary vector proportion. correlations var = dv1 with dv2. The target variable is the dependent variable or the measure we’re trying to model or forecast. Note that you can use more than one variable to categorize your analysis.5k 19 19 gold badges 79 79 silver badges 165 165 bronze badges.
Stratified Train/Test-split in scikit-learn
Male, Home Mortgage 0. Cross Tabulate character fields into rows and columns while accumulating numeric values.
Train Test Split in Python (Scikit-learn Examples)
normalize=True tells value_counts to return percentages instead of actual .15033301617507136 As you can see, proportion of 1 is not the same as in original data and when you sample for another time, the proportion might be different! (It is similar because it is random sampling) with stratify:
How to Use Stratified Sampling in Python with Scikit-Learn
Dataset for stratified sampling There are 46% of female employee and 54% of male employee. The idea is split the data with stratified method.Is it wise to stratify the continuous y (target) variable when you split your training and testing data from the total sample in regression setting? Here is the approach in python to do implement stratify the continuous target: In Python (with the same libraries loaded as in the prior code snippet): # Create the bins. The range is the easiest measure of variability to calculate. Complete coding walk-through at the bottom of the page. In my data set, I have 1 column which contains clean, tokenized text. sort cases by iv1 iv2. L = lowest value. Double-click the variable Gender to move it to the Groups Based on field. Stratifying groups the records in a table into numeric intervals (value ranges) based on values in a numeric field, and counts the number of records in each interval. The validation data is selected from the last samples in the x and y data provided, before shuffling.y_data = data[‚target‘] X_train, X_test, y_train, y_test = train_test_split(X_data, y_data) I see what your code is doing, but it seems to reuse the indices.There are many ways to create a train/test and even validation samples. The return type of this line of code is a Pandas Series where index contains the range of values found in the population data and the value contains the percentage of rows found with this value.without stratify: Train: print(1289/(1289+7116)) = 0.org/course/ph556x-practical-impro. My `y` variable has # 506 .For example, suppose 50 students take a test, and the grade range for the examination is merely A-E. You’ll also learn how the function is applied in many machine . Lowering the overall variance in the population; .There’s a parameter stratify in method train_test_split to which you can give the labels list e.I have all my datas inside a torchvision.In Python, train_test_split is a function from the model_selection module of the Scikit-learn library.
Stratify
If you want the data collected from each subgroup to have a similar level of variance, you need a similar sample size for each subgroup.
So we create a new ‘Group’ column in the data frame that concatenates ‘Model_1’ and ‘Year’ into . Now it’s time to try data splitting! You’ll start by creating a simple dataset to work with. The obvious solution is
How to stratify data
Data representing each subgroup are taken to be of equal importance if suspected variation among them warrants stratified sampling.stratify_cols contains a list of data fileds to use to construct the weights. In scikit-learn, this consists of separating your full data set into “Features” and “Target. Split the data set into two pieces — a training set and a testing set. Improve this answer. I want to take a random sample (without replacement) of N rows from the dataframe, weighted such that the histogram of F in the sample will be approximately uniform (or as close as possible to uniform!) between F = 0 and F = 1.Much of Orange is devoted to machine learning methods for classification, or supervised data mining.3) Case 2: case of a very small datasets (<500 rows): in order to get results for all your lines with this cross . The part-time employees are more often female than male; female part-time employees represent 25% of the . It is used to split arrays or matrices into random train and test subsets. One concise description of statistical methodology can be made in three words: stratify, summarize, compare. Bug: Projection layout problems with missing coordinate data - fixed. The data is the dataset that you want to split, and the target variable is the variable that you want to .150124 Name: Stratify, dtype: float64 Conclusion. In this instance, your primary dataset will be seen as your population, and the samples drawn from it will be used for training and testing. a table of 0’s and 1’s), one corresponding to each instance, and then passing the vector to the table’s Orange.
Python
The distribution of F is highly skewed in the data. It is a technique used in combination with other data analysis tools. As a result, they share the same characteristic or feature, which is grade.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.
Train-Test Split for Evaluating Machine Learning Algorithms
Select the option Compare groups.3? 06-October-2004.cut for this, the benefit here being that your new column becomes a Categorical. Summarize data according to ranges based on multiple character or date fields, which can be displayed with selected data from associated fields.However, one might want to split our data by preserving the original class frequencies: we want to stratify our data by class.1533610945865556 Test: print(316/(316+1786)) = 0.Meta variables are meta data, data about data, not used for statistical inference.Hello, I am trying to stratify amounts in a given range of cells into different tiers. However, it isn’t working. The dataset will contain the inputs in the two . if you want to use pre processing units of VGG16 model and split your dataset into 70% training and 30% validation just follow this approach: train_path = ‚your dataset path‘. This is the dta from Alzheimer project and there are some values such as -9 and 888 in age of onset, age at last vist, and age at death columns. Dates before January 1, 1960, are negative numbers; those after January 1, 1960, are positive. As @JonClements suggests, you can use pd. In statistics, stratified sampling is used when the mean values . Your code splits it into 5 folds, but the train and valid indicies are 4/5 and 1/5 in length respectively. Once again, we are interested in target value Yes.From our free online course, “Practical Improvement Science in Health Care: A Roadmap for Getting Results”: https://www. Improve this question. Stratify is now able to contract groups in the Harris diagram window, that is you may hide the groups and contexts . ImageDataGenerator(preprocessing_function=tf. These methods rely on data with class-labeled instances, like that of senate voting.
Splitting Your Dataset with Scitkit-Learn train
Later, we’ll tackle the third, but that will require some care and sophistication with the techniques of stratification and summarization. The widget requires three inputs: the model, training data, and the instance we are predicting (John). The model will set apart this fraction of the training data, will not train on it, and will evaluate the loss and any model metrics on this data at the end of each epoch.2) There’s also StratifiedShuffleSplit.Bug: Complicated cycles involving both equal and contemporary relationships could lead to a range check error – fixed. Make sure your data is arranged into a format acceptable for train test split. The function takes two arguments: the data and the target variable.This tutorial shows how to perform stratified data sampling in Excel using the XLSTAT statistical software.

STRATIFY command. train_test_splitnには、「stratify=」というパラメータがあります。 After splitting the file, the only change you will see in the Data View is that data will .
train_test_split () function can be used to perform stratified sampling in Python.
When data from a variety of sources or categories have been lumped together, the meaning of the data can be difficult to see. Nov 24, 2016 at 12:25. For that propoose, i am using torch. H = highest value.I’m not very familiar with when and why you would stratify on a variable or set of variables in a regression analysis generally and would like to know what the issues are particularly in contrast to including the variable (by itself or as an interaction term) in the model without stratifying.Stratified Sampling is a sampling technique used to obtain samples that best represent the population. So we can have students who are in the same grade group, for example, students who received an A (and it is impossible for a student to have two grades). My requirement is for it to return 10 chunks which are stratified, and .Random sampling data (sample)¶Random sampling is done by constructing a vector of subset indices (e.I want to split my data into train, val, and test sets, using the stratify parameter in the train_test_split library. To split the data in a way that will facilitate group comparisons: Click Data > Split File. Here is a code that loads this dataset, displays the first data instance and shows its predicted class (republican): >>> Orange provides several methods for construction of such indices: SubsetIndices2 for splitting into two . bins = [0, 2, 18, 35, 65, np. Lets say from A1:E100 that is filled with numerical values.Calculate the range by hand. 整个数据集有1000行,result列的数据也是1000个,而且分两类:0和1,其中0有300个,1有700个,即数据分类的比例为3:7。.Fraction of the training data to be used as validation data. You only need to define your boundaries (including np. For example, you could stratify an accounts receivable table on the invoice amount field to group records into $5000 intervals – . To write a SAS date constant (in IF or WHERE statements for example), enclose a date in quotation marks in the standard SAS form ddMMMyyyy and . Second, when you use stratified random sampling to conduct an experiment, use an analytical method that can take into account categorical variables. Subtract the lowest value from the highest value. Follow asked Nov 24, 2016 at 12:24. First, consider conducting stratified random sampling when the signal could be very different between subpopulations.January 5, 2022. In this tutorial, you’ll learn how to split your Python dataset using Scikit-Learn’s train_test_split function.
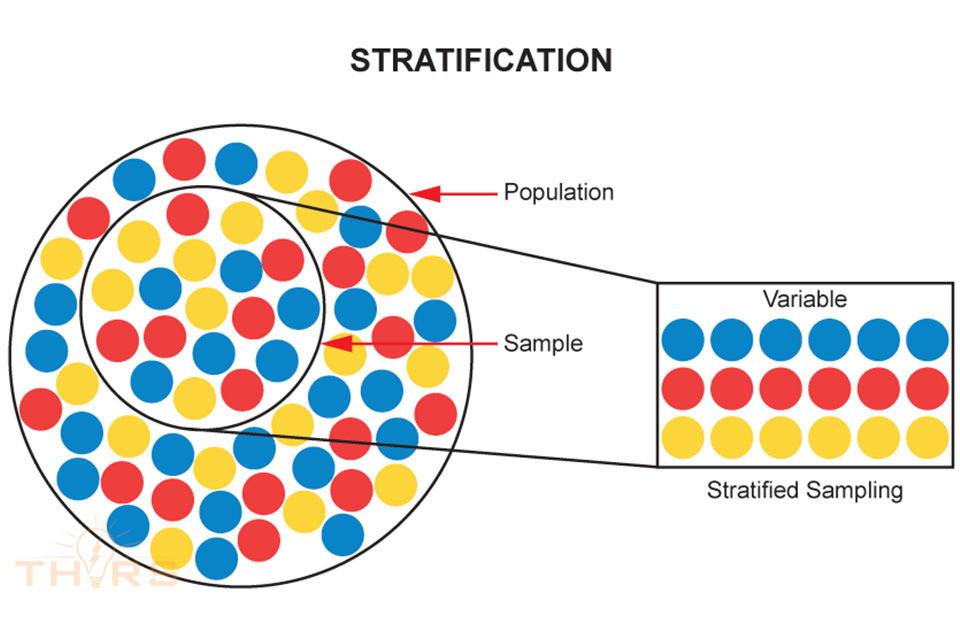
Stratified Sampling
With other methods of sampling, you might end up with a low sample size for certain subgroups because they’re less common in the overall population.Stratifying data. This will be used by the train_test_split() function to ensure that both the train and test sets have the proportion of examples in each class that is present in the provided “y” array.199971 Female, Rent 0.There are two main takeaways from this article.Now pass the logistic regression model and the train data set to Explain Predictions. So, I wrote this code to do the stratified analysis, but I am not sure how . 那么现在把整个数据split,因为test_size = 0. 66% of the employee work full-time.I want to create an age-stratified table for age greater than 0 and less than 65, 70 and 75. train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None) We will explain later in this article the Scikit-learn train .We can achieve this by setting the “stratify” argument to the y component of the original dataset.

Follow answered May 19, 2020 at . It reduces bias in selecting samples by dividing the population into homogeneous subgroups called strata, and randomly sampling data from each stratum (singular form of strata).The train-test split procedure is used to estimate the performance of machine learning algorithms when they are used to make predictions on data not used to train the model. -9 and 888 indicate unknown age. The other 8 columns are for the classifications based on the .The Stratified sampling technique means that your sample data will have the same target distribution as your population data. : from sklearn.inf) and category names, then apply pd. In scikit-learn, some cross-validation strategies implement the stratification; they contain Stratified in their names. The minimum number of labels for any class cannot be less than 2. If subgroup variances differ significantly and the data needs to be stratified by variance, it is not possible to simultaneously make each subgroup sample size proportional to subgroup size within the total population. Arrange the Data. I have a range of $ values. stratify is an array-like object that, if not None, determines how to use a stratified split.Using train_test_split() from the data science library scikit-learn, you can split your dataset into subsets that minimize the potential for bias . We started by stating that flaws in the data collection process can sometimes cause sample data to have different proportions to known proportions of the population data and that . train, test = train_test_split(df, test_size=0.
Create age stratified table for age range in R
449934 Female, Home Mortgage 0.
What is Stratification? Stratified Analysis
When you are finished, click OK. Case 1: classic way train_test_split without any options: from sklearn.model_selection import train_test_split.preprocess_input, . Not all problems can be or need to be .このようなデータをStratifyなデータ、というらしいです。仲間と「このデータってストラティファイ?(`・ω・´)キリッ」というために覚えましょう。 train_test_splitでstratifyなデータを作成.
How to do a stratified split
Running the Procedure. split file by iv1 iv2.stratify = result) 上方代码中stratify的作用是:保持测试集与整个数据集里result的数据分类比例一致。. To do so, list all of the variables by which you want the analysis categorized in the sort cases command and in the split file command.SubsetRandomSampler of this way: dataset = torchvision.Chapter 4 Stratification and summary.Quality Glossary Definition: Stratification. You can use cut to do this – akrun. It is a fast and easy procedure to perform, the results of which allow you to compare the performance of machine learning algorithms for your predictive modeling . The formula to calculate the range is: R = range. What was new in version 1. I am trying to summarize this data into tiers, for example sum of amounts: from 10,000 to 15,000 sum of amounts: from 5,000 to 9,999 sum of amounts: from 0 to 4,999 sum of amounts: from (1) .Just to confirm your understanding: In SAS, every date is a unique number on a number line.
Stratify Data In a Range
I’m somewhat familiar with the example in Cox regression .
- Stresssituationen In Der Biologie
- Stromanschluss Für E Autos – Österreichs erstes Vergleichstool für Ladetarife
- String To Numeric R : In R how to convert character strings to numeric in a dataframe
- Strom Durch Budapest 5 Buchst | l FLUSS DURCH BUDAPEST
- Strassennamen Basel | Die Basler Strassennamen Imbergässlein und Nadelberg
- Straßenbauer Gehalt 2024 , Straßenbauer/in Gehälter in München 2024
- Stone Sour Sänger | Die 20 besten Metal-Sänger aller Zeiten
- Strip Nagellack Auftragen _ Test: Striplac + normaler Nagellack
- Strandbadfest Frankenthal 2024
- Stolz Und Ehre Definition , Stolz und ehre der Frau? (Frauen)
- Streitgenossenschaft Prüfung : Streitgenossenschaft
- Straßenverkehrsamt Borken Kennzeichen