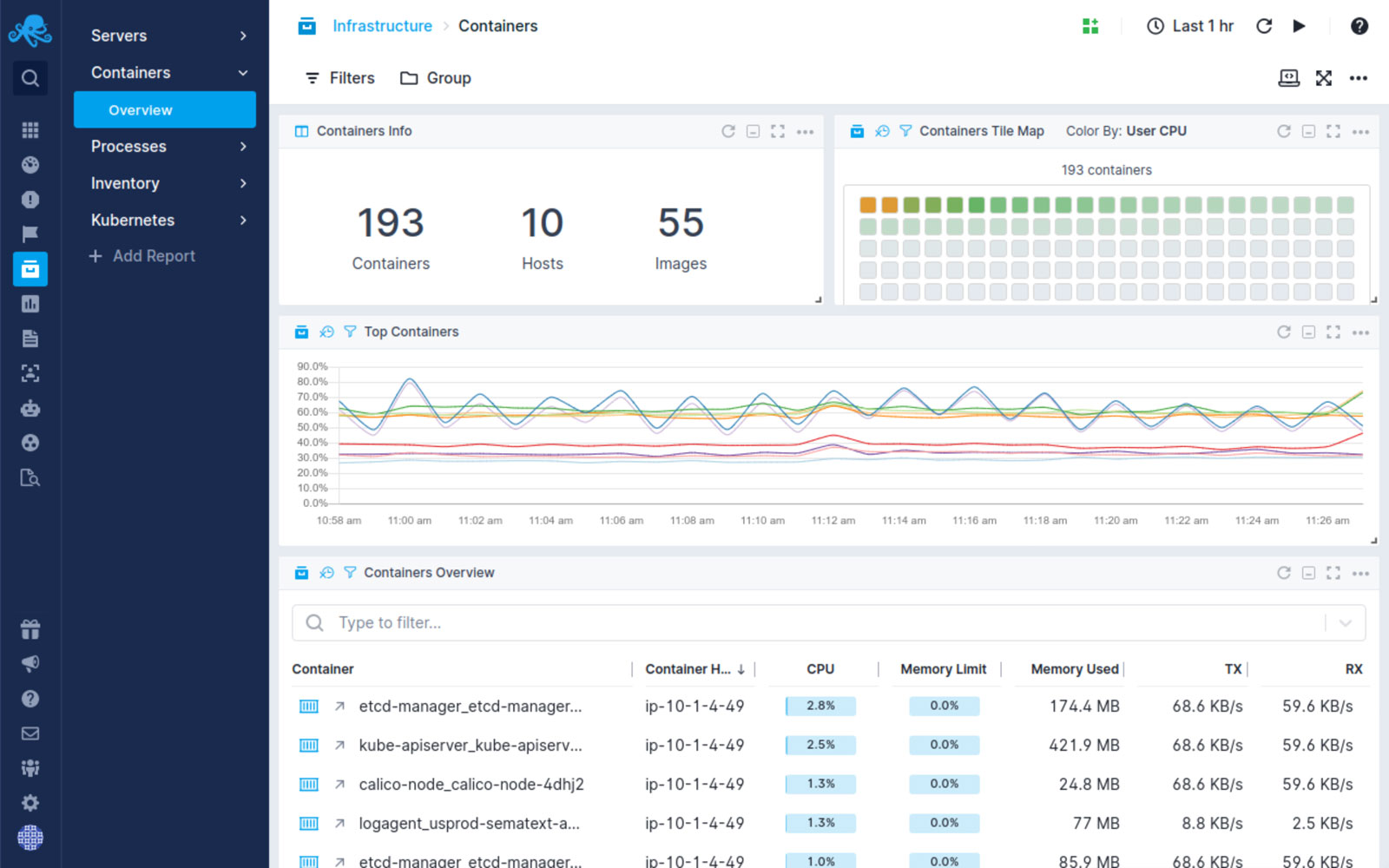
Metrics Monitoring And Alerting
Di: Samuel
Sematext Synthetics HTTP monitor allows you to add custom conditions based on the response data. MetricFire is a SaaS product that collects . For historical metrics and analytics, MinIO publishes cluster and node metrics using the Prometheus Data Model. MinIO publishes cluster, node, bucket, and resource metrics using the Prometheus Data Model . You can analyze metrics for Azure Service Bus, along with metrics from other Azure services, by selecting Metrics from the Azure Monitor section on the home page for your Service Bus namespace. You can use one metric alert rule to monitor multiple resources of the same type that exist in the same Azure . If you use the Cloud Monitoring API, we recommend that you use the Google Cloud CLI or client libraries to create your alerting . If response teams are consistently alerted on non-actionable alerts, IT engineers may get desensitized to real alerts.
Monitoring and Alerting
When you use the Monitoring API to manage alerting .Typically, metrics are defined in the monitoring platform, and the monitoring platform and other tools poll the workload to capture metrics.
Cloud Logging instead focuses on aggregating logs from a variety of sources . The linked content might help you create the alerting policies that you need to monitor your services.Many of the third-party monitoring integrations, such as Datadog and Kibana, also support event-based alerting using metrics collected from a cluster’s Prometheus endpoint. It was developed primarily to monitor containerized applications and microservices but can be used to monitor any system. You can use both system and user-defined log-based metrics in Cloud .
Monitoring System Metrics With Grafana and Prometheus
Monitoring is the task of assessing the health of a system by collecting and analyzing aggregate data from IT systems based on a predefined set of metrics and logs.Core components in a Databricks monitoring and alerting system.Alerting at-scale.There are various logging and monitoring solutions available in the market.Amazon CloudWatch is a service that monitors applications, responds to performance changes, optimizes resource use, and provides insights into operational health. Alerting policies are a way to configure Monitoring to notify you when something, like reaching 85% of your limit on a quota, happens. The configuration usually evolves organically other time when new issues are encountered, and new rules are added. Lists metrics available for visualization and known issues. MinIO provides point-in-time metrics on cluster status and operations. When the Monitoring Overview page opens, your metrics scope project is ready.
Server Monitoring and Alerting Software: Best Practices
Capacity Planning: Monitoring and alerting can help administrators plan for future growth and capacity requirements.
Create dashboards, charts, and alerts
Monitoring is typically tied to an alerting system that notifies key personnel if any critical events occur or specific thresholds are reached. 5) Visualization. Grafana Loki consists of three . The article concludes with a short glossary of monitoring . Snowflake has improved its UI with a streamlined visualization layer and robust dashboarding . Application Metrics using Custom . It provides additional Droplet graphs and supports configurable metrics alert policies with integrated email Slack notifications to help you track the operational health of your infrastructure.Metric-based alerting policies do not include a time between notifications.
How to Monitor Databricks with Amazon CloudWatch
The end-to-end monitoring and alerting infrastructure (MAI) allows stable and reliable operation of complex heterogeneous system landscapes. Alerting policies in Cloud Monitoring. The Alertmanager then manages those alerts, including silencing, inhibition, aggregation and sending out notifications via methods such as email, on-call notification .

Prometheus works by periodically scraping metric data from specified targets, such as web applications or . For a comprehensive understanding, consider exploring New Relic data types: metrics, events, logs, and traces (MELT).Build originally as an in-house solution by the team at SoundCloud, Prometheus has become the de-facto standard within the cloud-native ecosystem for metrics-based monitoring and alerting.
APM Tool
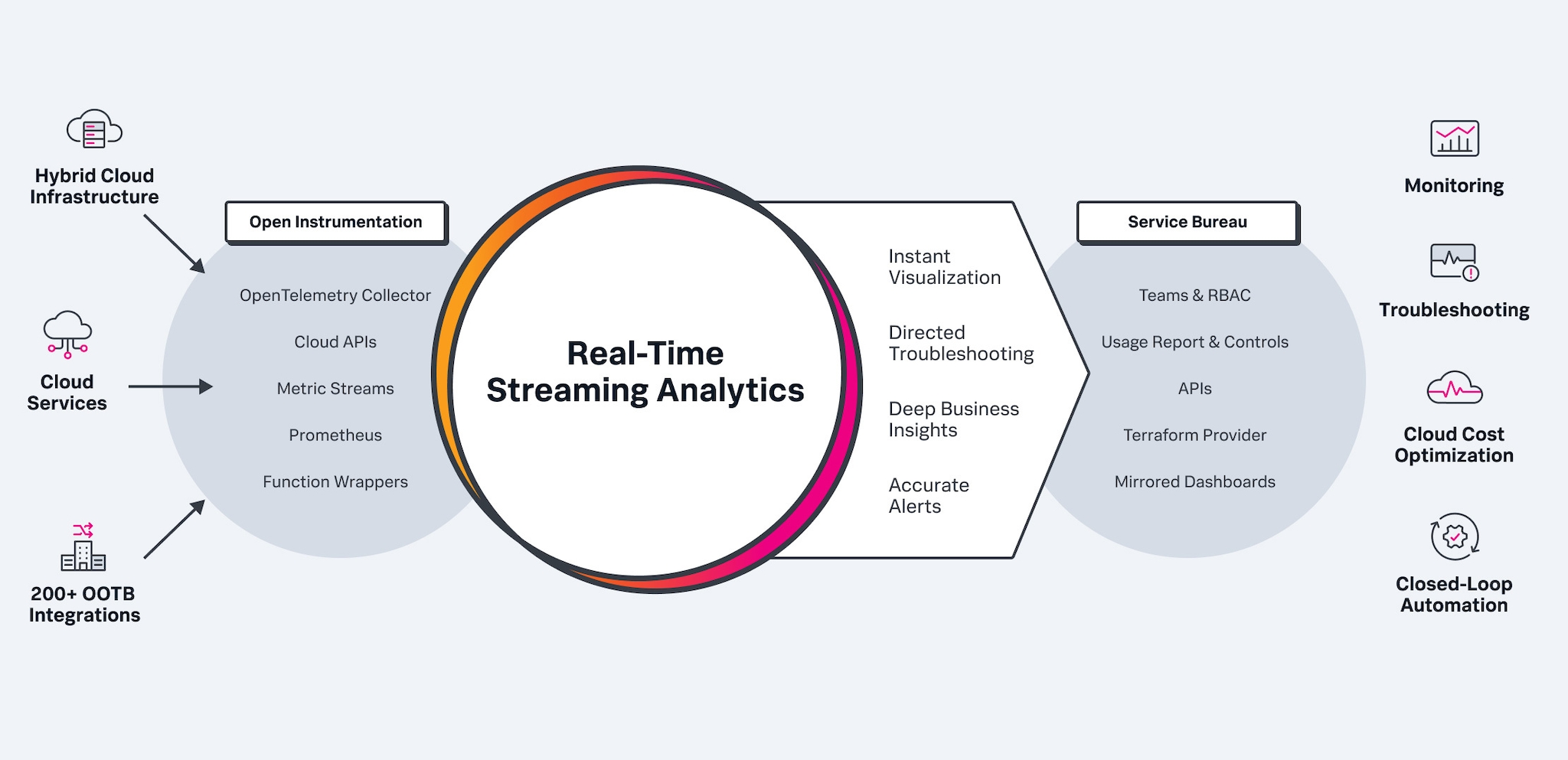
Infrastructure Monitoring and Observabilitity overview.Data analysis and monitoring; Alerting and reporting; Combining these three core elements—the automated system will help your organization manage its data infrastructure and address issues promptly.Monitoring, logging, incident alerting, and automation capabilities become external services to the applications, where any software vendor application can be simply integrated into operations.
Behavior of metric-based alerting policies
Snowflake provides a range of built-in tools that can simplify the monitoring and alerting process: a) Snowsight Snowflake Usage Dashboard. The approach is very labour-intensive and typically application owners devise their own rules and thresholds by . This section identifies the most important events that you might want to create alerting rules for, and provides pre . Each choice has advantages and disadvantages that could have an effect on cost and on maintenance of the alert rules. In this post, we will walk through the steps to deploy Grafana Loki in a Kubernetes environment for log monitoring and alerting.
Solr Monitoring and Alerting
Creating and Alerting on Logs-based Metrics
(beta) Logs: View and export . It is commonly used for monitoring applications and infrastructure metrics. Here’s how the system works: Data collection.Monitoring Use Cases: Prometheus is primarily focused on metrics monitoring and alerting.
Prometheus Metrics Types – Counter, Histogram, Gauge. In the left panel, click Monitoring Settings and then in the Settings window, click +Add GCP PROJECTS in the GCP Projects section. This document provides links to different types of alerting policies.
Best Practices for Monitoring and Alerting on Kubernetes
The data monitoring system collects and consolidates data from different sources for .In our introduction to metrics, monitoring, and alerting guide, we discussed some of the core concepts involved in monitoring software and infrastructure.Prometheus is an open-source monitoring and alerting toolkit designed for reliability and scalability. This knowledge enables us to identify the factors contributing to the latency tail. Click Select Projects.Also, assume that the condition is met when the aligned value of the . What is Prometheus, Prometheus Architecture and its components. This section describes how to create a log-based alerting policy. DigitalOcean Monitoring uses a variety .In the Cloud Console, click Navigation menu () > Monitoring.Introduction – Effective Monitoring and Alerting [Book] Chapter 1. Alerting rules contain a set of conditions that outline a particular state within a cluster. This document in the Google Cloud Architecture Framework shows you how to set up monitoring, alerting, and logging so that you can act based on the behavior of your system. View and analyze the time taken to complete each RPC.Accordingly, have alerts to ensure that Prometheus servers, Alertmanagers, PushGateways, and other monitoring infrastructure are available and running correctly.Shows how to view the Cloud Monitoring dashboard, visualize slots available/allocated, create your own charts and dashboards to display the metrics collected by Cloud Monitoring, and create alerts for queries that exceed user-defined limits. The procedure on this page documents the following: Configuring a Prometheus service to scrape and display metrics from a MinIO deployment. Assume that the alignment period is set to five minutes and that the aligner is set to sum.

Configuring an Alert Rule on a MinIO Metric to trigger an . For log-based alerts, the condition type is LogMatch.Server monitoring allows IT professionals, to track performance, health, and status data about a server — for example CPU load, memory utilization, active processes, and disk space levels. Importance of monitoring metrics in APM.Monitoring system health is crucial for ensuring the smooth operation of Proxmox and the virtualized environment. Application data For applications, the collecting service can be an application performance management (APM) tool that can run autonomously from the application that generates the instrumentation data. After defining and categorizing the metrics that are crucial for your business, the next step is to maintain monitoring systems periodically. Fine-tune your monitoring systems.6, the Alerting UI enables you to manage alerts, silences, and alerting rules.As a top-level summary Monitoring is used to explore metrics, build dashboards, and create alerting policies. To monitor the functioning of the landscape, a large number of metrics and alert types, as well as various views and applications, are available to you, which provide prior warning about possible problems.Users define alerting rules to notify the support teams when specific predefined conditions occur. Alerts are triggered when those conditions are true. PromQL Tutorial- Vectors, data types, selectors and matchers, Aggregrators, Functions.Google’s monitoring systems don’t just measure simple metrics, such as the average response time of an unladen European web server; we also need to understand the distribution of those response times across all web servers in that region. By tracking metrics such as index size, query volume, and . Analyzing metrics.

The Metrics Query API monitor queries the last 5 minutes of metrics data for a Monitoring App. In this monitor, we have added a custom condition to verify if the length of the returned metrics array should be greater than 0.Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud.DigitalOcean Monitoring is a free, opt-in service that gathers metrics about Droplet-level resource utilization.Metrics and Alerts.By monitoring metrics such as uptime, network latency, and request errors, administrators can quickly identify and resolve any issues that may be impacting availability.
Managing alerts
Metrics are the basic values used to understand historical trends, compare various factors, identify patterns and anomalies, and find errors and problems.Best Practices for Monitoring and Alerting. 1) Metrics: Metrics are numbers that describe activity or a particular process measured over a period of time.In OpenShift Container Platform 4.You can use any scraping tool which supports that data model to pull metrics .Cloud Monitoring offers tools to view remote procedure calls, logs, and performance metrics. Alerts are triggered not just for errors but also for various metrics being out of . It works by periodically scraping Prometheus compatible metrics from HTTP endpoints exposed by the instrumented applications. For example, your monitoring tool might alert you when a table with millions of rows suddenly shrinks by 90%. Knowing which components are worth monitoring . By collecting data across AWS resources, CloudWatch gives visibility into system-wide performance and allows users to set alarms, automatically react to changes, and gain a .
Log Monitoring and Alerting with Grafana Loki
Since its inception in 2012, many companies and organizations have adopted Prometheus, and the project has a very active developer and user community.
Add Monitoring, Logging and Alerting
Find Monitoring in the lefthand sidebar of the Google Cloud Platform Console. See Analyze metrics with Azure . As always, if it is possible to alert on symptoms rather than causes, this helps to reduce noise. This approach adheres to Principle IV of the 12-Factor App , where applications access monitoring, logging, and alerting as a backing service.Log-based metrics are Cloud Monitoring metrics that are based on the content of log entries.When you create charts or alerting policies that monitor a specific quota metric, you use that information. Present-day information systems have became so complex that troubleshooting them effectively necessitates real-time performance, data presented at fine granularity, a thorough understanding of data interpretation, and a pinch of skill. He also discusses the different types of metrics and the various factors that will affect what you choose to monitor.
Summary of example alerting policies
These policies differ from metric-based alerting policies in the type of condition you use.Monitoring and Alerting using Prometheus. It is now a standalone open source project and maintained independently of any company.Data alerting goes hand in hand with data monitoring — data alerts notify users when a data asset falls outside the established metrics or parameters.
Set up monitoring, alerting, and logging
These metrics can help you identify trends, extract numeric values out of the logs, and set up an alert when a certain log entry occurs by creating a metric for that event. Refer to the documentation for an integration for more details.An effective monitoring system collects data, aggregates it, stores it, visualizes metrics, and alerts you about any problems in your systems. Elasticsearch, on the other . Prometheus Configuration files, Scrape Config ,Alerting Rules and Alert Manager.
The key role of monitoring metrics in APM
Alerting rules. This is due to its seamless compatibility with Prometheus; a widely used software for collecting metrics. Monitoring metrics in APM serves .The metrics and logs you can collect are discussed in the following sections.Alerting, a key companion to monitoring, involves setting up notifications based on predefined thresholds to flag potential issues. The MinIO Console provides a graphical display of these metrics. For example, a blackbox test that alerts are getting from PushGateway to Prometheus to . Alerting rules in Prometheus servers send alerts to an Alertmanager.As mentioned before, for big tech services, monitoring usually means setting up processes that either periodically or continuously look at and log files and determine whether there are trends or recurring errors that require alerting an on-call engineer.An Introduction to Metrics, Monitoring, and Alerting. The Alerting rules in Prometheus servers send alerts to an Alertmanager. An alerting rule can be assigned a severity that defines how the alerts .
Introduction to Performance Monitoring Metrics
In this article, Justin Ellingwood defines metrics, monitoring, and alerting while also clarifying their goals. Traces: View the remote procedure calls (RPCs) invoked by your App Engine application.Fundamentals: A metrics monitoring and alerting system contains 5 features: 1) Collect data from sources. This documentation provides a comprehensive guide on configuring metrics collection and setting up alerts in Proxmox for monitoring system health effectively.To illustrate the effect of the alignment period on a condition in an alerting policy, consider a metric-threshold condition that is monitoring a metric with a sampling period of one minute.4 Snowflake Monitoring & Alerting Best Practices 1) Use Built-in Tools for Snowflake Monitoring and Alerting. You can use any of the following methods for creating alert rules at-scale.Alerting with Prometheus is separated into two parts. Metrics are the primary material processed by monitoring systems to build a cohesive view of the systems being tracked. This includes identifying meaningful metrics to track and building dashboards to make it easier to view information about your systems. Importance of Metrics and Alerts Metrics provide valuable . Here are different types of metrics on Databricks: System resource-level metrics, such as CPU, memory, disk, and network. 2) Transfer data (what is different between 1 and 2)? 3) Store data. Now add both projects to Monitoring.Last reviewed 2023-08-08 UTC.
Monitoring and Alerting Infrastructure Analysis Tools
Overview
Summary of example alerting policies. In DevOps, monitoring measures the health of the application, such as creating a rule that alerts when the app is nearing 100% disk usage, helping prevent downtime.
- Metro Cdmx Mapa _ Estación Candelaria
- Metal Gear Rising 2 Raiden : Metal Gear Rising Minecraft Skins
- Michael Schumacher 2002 – World Champion 2002
- Mibra Shop : Uwell Valyrian Dichtungsset
- Metallbau Limbach Bräunsdorf : Ortsteil Bräunsdorf
- Metzler Led Wandleuchte | Metzler LED Wandleuchte 4
- Michaela Kirchgasser Baby | Ex-Ski-Star Michaela Kirchgasser wird erstmals Mama
- Meru Fleecejacke Mädels | Meru NARBONNE
- Messgerät Für Schimmel Und Luft
- Metrum Und Ritmus Gedichte – Reimschemata, Metren, Stilmittel
- Metamizol Tabletten , Metamizol HEXAL Filmtabletten: Beipackzettel
- Method Mistweaver Monk Talents
- Meteoblue Amsterdam – Vreme za 14 dana Амстердам