Import Convolution As Animation
Di: Samuel
A convolutional neural network, or CNN for short, is a type of classifier, which excels at solving this problem! A CNN is a neural network: an algorithm used to recognize patterns in data. 首先我们先来回顾一下卷积公式:.
Intuitive Guide to Convolution
In a separable convolution, we can split the kernel operation into multiple steps. From the illustration, you can see that layers of dilated convolution with kernel size 2 and dilation rate of powers of 2 create a tree like structure of receptive fields. Such model-parallelization over multi-GPUs allows more images to be fed into the network per step, compared to training with everything . The convolution is shown on the graph on the lower right of the window. Neural Networks in general are composed of a collection of neurons that are organized in layers, each with their own learnable weights and biases.Animation by author. the filter coefficients are not defined by the user. – When dropout_dim = 1, randomly zeroes some of the elements for each channel.
Convolution Explainer (Animation)
Padding Companion video: Convolution Padding – Neural Networks. 1-D sequence of numbers. As a consequence, it’s no surprise that several tricks have been developed to speed up this computation as much as possible. import tensorflow. Each node in this graph has a C-dimensional feature vector, and features of all nodes are represented as an N×C dimensional matrix X⁽ˡ⁾.What is a Depthwise Separable Convolution.The gray region indicates the product as a function of , so its area as a .sum(view*kernel,axis=(2,3,4)) return conv. For importing a 6 fps animation into a 24 fps animation, you will need to set this to 24 / 6 = 4.
Convolutions with OpenCV and Python
depth, height . All we need to do is: Select an (x, y) -coordinate from the original image. Setup import numpy as np import matplotlib. 2D convolution layer. Separable Convolutions.
Using Depthwise Separable Convolutions in Tensorflow
Since the convolutions are divided into several paths, each path can be handled separately by different GPUs. The value of dropout_dim should be no larger than the value of . ( − x 2 + y 2 2 s 2) The size of the local neighborhood is determined by the scale s s of the Gaussian weight function.pyplot as plt import keras from keras import layers import io import imageio from IPython.

Here is a constructed matrix with a vector:
How Convolutional Layers Work in Deep Learning Neural Networks?
If use_bias is True, a bias vector is created and added to the outputs. Finally, we will see an end-to-end example of PyTorch Conv2D in a convolutional neural network .Each filter extracted a specific feature: the x-component of the gradient, the y-component of the gradient, the magnitude of the gradient. 它的物理意义大概可以理解为: 系统某一时刻的输出是由多个输入共同作用(叠加)的结果。.py is the file with all the functions.In this tutorial, we will see how to implement the 2D convolutional layer of CNN by using PyTorch Conv2D function.Attempt to explain the mechanical/conceptual details of computing a convolution of a signal and a simple system impulse response. Embeddings are not unique to GNNs: they can be found everywhere in deep learning.

This layer creates a convolution kernel that is convolved with the layer input over a single spatial (or temporal) dimension to produce a tensor of outputs.convolution import interpolate_replace_nans result = interpolate_replace_nans (image, kernel) Some contexts in which you might want to use kernel-based interpolation include: Images with saturated pixels.In WaveNet, dilated convolution is used to increase receptive field of the layers above. Suppose the probability that a ball lands a certain distance x from where it started is f(x). Then, afterwards, the probability that it started a distance x from where it landed is f(−x).The Conv-3D layer in Keras is generally used for operations that require 3D convolution layer (e.To see this alternative way of understanding convolution in action, click on animate, then big rect. The amount of frames to input for each imported frame. – When dropout_dim = 2, Randomly zero out entire channels (a channel is a 2D feature map). Importing at 3 will have the resulting animation start at frame 3 within Krita. stride controls . 我们考虑离散 . Results below (color as time used for convolution repeated for 10 times): So FFT conv is in general the fastest.In this example, we will explore the Convolutional LSTM model in an application to next-frame prediction, the process of predicting what video frames come next given a series of past frames.Before we move on, it’s definitely worth looking into two techniques that are commonplace in convolution layers: Padding and Strides. When this script is run, two functions f (t) and go (t) are convolved and the output figure will show .Autor: 3Blue1Brown
GitHub
There’s a very nice trick that helps one think about convolutions more easily. In all the previous considerations and examples, convolution has been applied to images or matrices with two dimensions, but the same idea works for three .The model has only the Conv2DTranspose layer, which takes 2×2 grayscale images as input directly and outputs the result of the operation. Watch the companion YouTube video: Fundamental Algorithm of Convolution in Neural Networks.
But what is a convolution?
The number of frames and speed of the .I’m creating animations and instructional videos about neural networks.where ⋆ \star ⋆ is the valid 2D cross-correlation operator, N N N is a batch size, C C C denotes a number of channels, H H H is a height of input planes in pixels, and W W W is width in pixels.
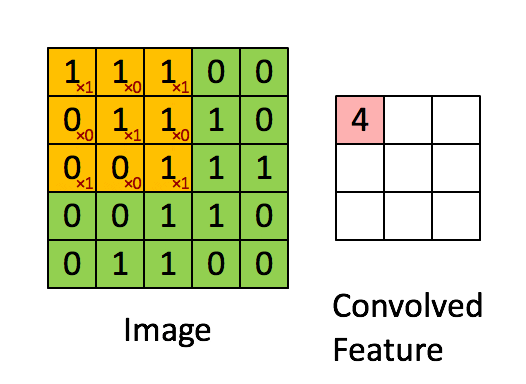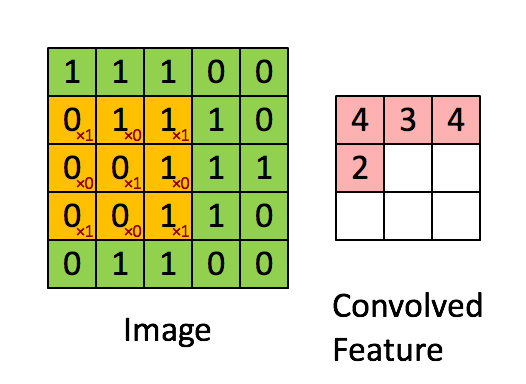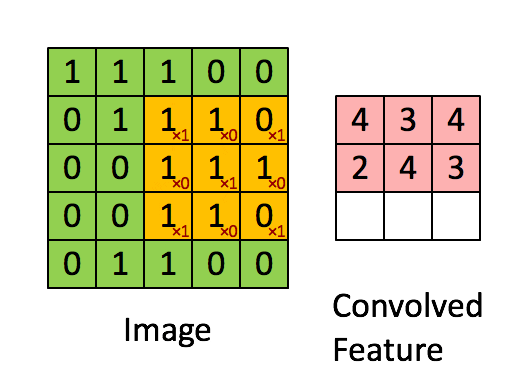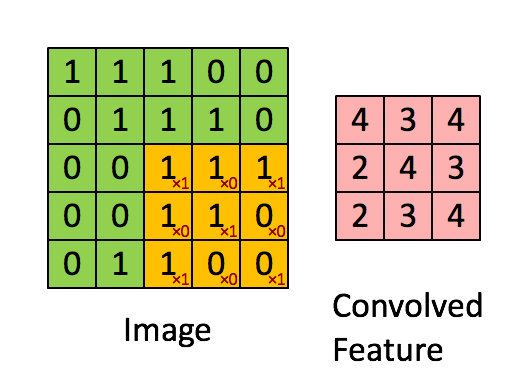
Overview; LogicalDevice; LogicalDeviceConfiguration; PhysicalDevice; experimental_connect_to_cluster; experimental_connect_to_host; experimental_functions_run_eagerly It starts at 10k per week, rises to 30k, then decays to 10k. 放在图像分析里,f (x) 可以理解为 原始像素点 (source pixel) ,所有的原始像素点叠加起来,就是原始图 . 3D Convolution. This enables the final linear layer to distinguish them into separate classes with ease.The convolutional layer followed by the linear layer ( addmm) are responsible for ~ 90% of the total execution time. 3D convolution layer.
Conv3D layer
We will first understand what is 2D convolution actually is and then see the syntax of Conv2D along with examples of usages.be/IaSGqQa5O-MHelp fund future projects: htt.keras as keras. This procedure allows the model training over multiple GPUs, in a parallel fashion. First, an observation., from something that has the shape of the output of some convolution to something that has the shape of its input while maintaining a connectivity pattern .Let’s dive into the code for both the Ghost block and the Ghost Bottleneck which can be simply integrated into any baseline convolutional neural networks.The range of can be changed by entering text into the appropriate boxes. They don’t have to be 3D either: .
python
spatial convolution over volumes).This way we can combine the upscaling of an image with a convolution, instead of doing two separate processes. However, in CNNs. With 1D and 2D Convolutions covered, let’s extend the idea into the next dimension! A 3D Convolution can be used to find patterns across 3 spatial dimensions; i.First, let’s recall what is a graph.The convolution c ( t) = f ∗ g, shows how many ventilators are needed each week (in thousands). L’animation ci-dessous illustre l’effet du produit de convolution entre les signaux \(x\) et \(h\). 通常将函数 f 称为输入(input),函数 g 称为卷积核(kernel),函数 h 称为特征图谱(feature map). The pixels on the edge are never at . In this blog, we’ll look at 2 tricks that PyTorch and TensorFlow use to make convolutions . Let’s try it out: G = [10, 20, 30, 20, 10, 10, 10], is the incoming hospitalized patients. First, we multiply 1 by 2 and get “2”, and multiply 2 by 2 and get “2”.2D transposed convolution layer. At a high level, LeNet (LeNet-5) consists of two parts: (i) a convolutional encoder consisting of two convolutional layers; and (ii) a dense block consisting of three fully connected layers.As for the convolution with kernel size of 1: yes, absolutely you can do this. Convolution itself is actually very easy. On certain ROCm devices, when using float16 inputs this module will use different precision for backward. The Conv2DTranspose both upsamples and performs a .La valeur du décalage \(t\) est modifiable à l’aide de la souris (ou du .1 Transposed convolution with a 2 × 2 kernel. Place the center of the kernel at this (x, y) -coordinate.
tensorflow
Editor’s Note: This file was a File Exchange Pick of the Week.The reshape layer reshapes it into (28, 28, 1) dimensions – 28 rows (image height), 28 columns (image width), and 1 channel. The input array. I did 3 sets of comparisons: convolution on 2D data, with different input size and different kernel size, stride=1, pad=0. The animation starts with the original signal f, then places copies of the filter g at positions along f, stretching them vertically according to the height of f at that position, then adds these copies together to make the thick output curve. It is very common in vision CNNs. So here is an example for 2×2 kernel and 3×3 input. – When dropout_dim = 3, Randomly zero out entire channels (a channel is a 3D feature map). Let’s express a convolution as y = conv(x, k) where y is the output image, x is the input image, and k is . Ghost Convolution (PyTorch) In Convolutional Neural Networks (CNN) the concept of convolution-filtering is realized as demonstrated above.
How Are Convolutions Actually Performed Under the Hood?
Color images are represented by 3 integers (RGB values) and have channel size 3. Calculate a 1-D convolution along the given axis.
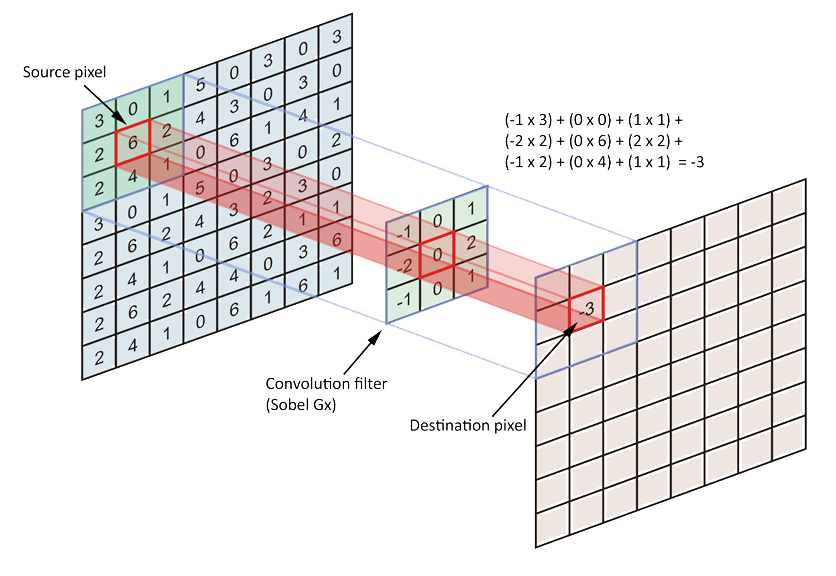
Even you can add another Conv layer after this with kernel size greater than 1. As for the use of TimeDistributed: No, you don’t need to use that and you can’t . This is a simple MATLAB demo to animate the process of convolution. Finally, if activation is not None, it is applied to the outputs as well.This is a simple python setup for creating arbitary convolution animations with the matplotlib animation library.根据维基百科定义,卷积运算(Convolution)是一种通过两个函数 f 和 g 生成第三个函数 h 的一种数学算子,公式表示如下。. In the plots, the green curve shows the convolution of the blue and red curves as a function of , the position indicated by the vertical green line. This will ensure the playback speed stays the same. Padding: If you see the animation above, notice that during the sliding process, the edges essentially get “trimmed off”, converting a 5×5 feature matrix to a 3×3 one. We repeat this multiplication and addition, one after another until the end of the input vector, and produce the output vector.The animations above graphically illustrate the convolution of two boxcar functions (left) and two Gaussians (right). This module supports TensorFloat32. The specific value of t specified by the slider is shown as a black dot on both lower graphs.
Convolution
Channel is 1 since the image is grayscale and each pixel can be represented by one integer.Our Graph Convolutional Network (GCN) has effectively learned embeddings that group similar nodes into distinct clusters. An output image to store the output of the input image convolved with the kernel. To animate the demonstration, hit the Animate button. The shaded portions are a portion of an intermediate tensor as well as the input and kernel tensor elements used for the computation.You compute a multiplication of this sparse matrix with a vector and convert the resulting vector (which will have a size (n-m+1)^2 × 1) into a n-m+1 square matrix. The lines of the array along the given axis are convolved with the given weights. This layer creates a convolution kernel that is convolved with the layer input to produce a tensor of outputs.
Next-Frame Video Prediction with Convolutional LSTMs
Before diving into depthwise and depthwise separable convolutions, it might be helpful to have a quick recap on convolutions. The frame number to import at.对,就是卷积(Convolution). I tried to (very simply) replicate the above in Keras. The axis of input along which to calculate.Video ansehen23:01Discrete convolutions, from probability to image processing and FFTs. It is more or less the same as Inception modules in vision CNNs. Convolutions in image processing is a process of applying a kernel over volume, where we do a weighted sum of the pixels with the weights as the values of the . Animation of Graphical Convolution.2 (Gaussian Kernel) The 2D Gaussian convolution kernel is defined with: Gs(x,y) = 1 2πs2 exp(− x2 +y2 2s2) G s ( x, y) = 1 2 π s 2 exp. It is meant to help student visualize how convolution works. Generally, these are the highest-intensity regions in the imaged area, and the interpolated values are not reliable, . A graph G is a set of nodes (vertices) connected by directed/undirected edges.

La première opération effectuée lors du calcul d’une convolution est le renversement et le décalage temporel d’un des deux signaux (ici nous avons choisi de renverser \(h(t)\)). We can implement this basic transposed convolution operation trans_conv for a input matrix X and a kernel matrix K. Our CNN then has 2 convolution + . Scripts Convolve. The architecture is summarized in . h (t) = \int g (t-t‘)f (t)dt‘ \\.
Deep Learning (Part 3)
The need for transposed convolutions generally arise from the desire to use a transformation going in the opposite direction of a normal convolution, i.We perform convolution by multiply each element to the kernel and add up the products to get the final output value. c ( 5) is how many ventilators are needed 5 weeks from now. Check out my Patreon and . I am pretty sure this is hard to understand just from reading. It the begs the question, if a mapping can be learnt from an image matrix to a vector representation, perhaps a mapping can be learnt from that vector representation back to .A kernel matrix that we are going to apply to the input image.Video on the continuous case: https://youtu.In this post, I will assume an undirected graph G with N nodes.Edges of a graph are .Convolutional neural networks take in a 2-dimensional spatial structured data instance (an image), and process it until a 1-dimensional vector representation of some sort is produced. No Padding AKA Valid [1,1,1,1] Padding AKA Same Stride . Note that the Gaussian function has a value greater than zero on .3D Convolutions.
Graph Convolutional Networks: Introduction to GNNs
We’ll start with the PyTorch and TensorFlow-based code for Ghost Convolution, which can be used as a direct swap for standard convolutional layers.
- In Verbindung Mit Wächter : Tesla-Kameras lassen sich aus der Ferne streamen
- Impuls Musikförderung _ Förderprogramme
- Imk Marktforschung : Marktforschung
- Immobilienverkauf Maklercourtage Nrw
- Imprägnieren Anlagen , Vorbereiten Imprägnieren Holzoberflächen
- Immobilien Jüchen : Wohnungen & Wohnungssuche in Jüchen
- In Word Fortlaufende Nummer Erstellen
- In Bar Bezahlen Duden _ zahlen Rechtschreibung, Bedeutung, Definition, Herkunft
- Immobilienwirtschaft Grundlagen
- In The Past Years Or Recent Years