Hadoop Framework Architecture – Apache Hadoop: MapReduce, HDFS, big data
Di: Samuel
0) is the second iteration of the Hadoop framework for distributed data processing.Hadoop is an open-source framework for organizing and storing large amounts of data across a network of computers through the use of parallel processing and efficient distributed data storage and retrieval. Dans cette chronique, nous allons vous indiquer comment utiliser hadoop et son écosystème technologique dans un projet Big Data. Hadoop architecture is created on Java and can only be used for offline processing.
Hadoop YARN Architecture
Hadoop : présentation et guide pratique
The blocks of a file are replicated for fault tolerance. Numerous vulnerability categories are studied in this research, .in/productsCloud Computing Notes:.
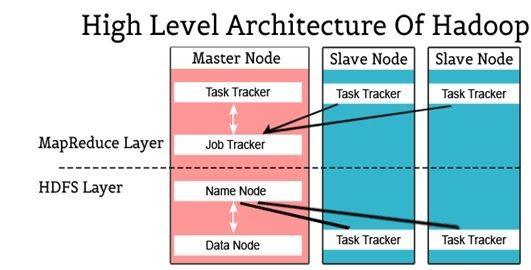
MapReduce is nothing more than an Algorithm or a Data Structure built on the YARN framework.Hadoop : définition, architecture, distributions. Last Updated : 18 Jan, 2019.Hadoop einfach erklärt! Apache Hadoop ist eine verteilte Big Data Plattform, die von Google basierend auf dem Map-Reduce Algorithmus entwickelt wurde, um rechenintensive Prozesse bis zu mehreren Petabytes zu erledigen. Hadoop is a framework that uses distributed storage and parallel processing to store and manage Big Data.Components of Hadoop Architecture .
Hadoop framework
Hadoop | History or Evolution.The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks. Its distributed file system enables processing and tolerance of errors. Il repose sur une infrastructure hautement scalable et un système de fichiers distribués (HDFS).universityacademy. En résumé, Hadoop est très utile pour le traitement du Big Data lorsqu’il implémenté et utilisé correctement.Hadoop YARN Architecture. Facebook created Hive in 2008 to address some limitations of working with the Hadoop Distributed File System.What Is a Hadoop Cluster? Apache Hadoop is an open source, Java-based, software framework and parallel data processing engine. There are mainly two problems with the big data. Hadoop is an open source framework overseen by Apache Software Foundation which is written in Java for storing and processing of huge datasets with the cluster of commodity hardware.The respective architectures of Hadoop and Spark, how these big data frameworks compare in multiple contexts and scenarios that fit best with each solution. Moreover, the architecture is designed to be highly scalable and fault .
Apache Hadoop: Advantages, Disadvantages, and Alternatives
Les données sont stockées sur des serveurs standard peu coûteux configurés en clusters. A Hadoop cluster .Dazu gehören die Java-Archivdateien (), die benötigt werden, um Hadoop zu starten, Bibliotheken für die Serialisierung von Daten sowie Schnittstellen für Zugriffe auf das . Cafarella, Hadoop uses the MapReduce .
What Is Hadoop? A Brief Guide
These weaknesses put the data at danger and attract attackers. Cost efficiency Though it’s not the main reason to opt for Hadoop, cost efficiency remains a strong argument in favor of the framework. Typically the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes. Hadoop is designed to scale up from single server to thousands of machines, each offering local computation and storage. Hadoop Architecture. Le système de fichiers distribué Hadoop supporte des fonctionnalités de traitement concurrent et de tolérance aux .Apache Hadoop is a powerful big data framework that allows organizations to store, process, and analyze large amounts of data. Mis à jour le 28/02/23 09:00.Hadoop: is an open-source distributed system produced by Apache. Socle technique du big data, Hadoop est un framework open source qui permet de stocker et de traiter de grands volumes de données.
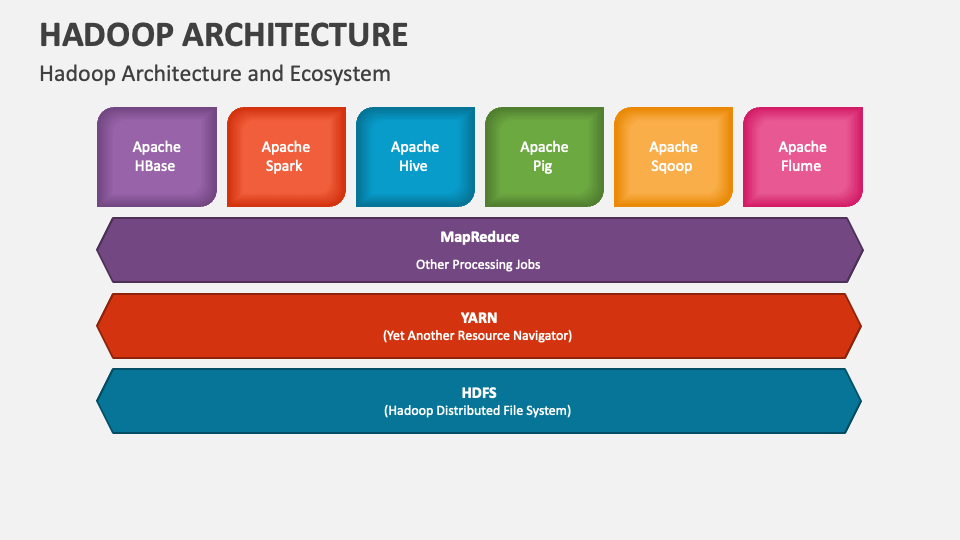
YARN was described as a “ Redesigned Resource Manager ” at the time of its launching, but it has now evolved to .YARN supports the notion of resource reservation via the ReservationSystem, a component that allows users to specify a profile of resources over-time and temporal constraints (e., deadlines), and reserve resources to ensure the predictable execution of important jobs. This post is part 1 of a 4-part series on monitoring Hadoop health and performance. It is designed to scale up from single servers to thousands of . The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. By creating a cost-effective yet high-performance solution for big data workloads, Hadoop led to today’s data lake architecture . Hadoop is an open-source framework for processing of big data. A proof of this is the number of publications about the framework, which amounts to a very large number over the past five years.The Apache® Hadoop® project develops open-source software for reliable, scalable, distributed computing. Part 2 dives into the key metrics to monitor, Part 3 details how to monitor Hadoop .Data Storage in Hadoop.
Was ist Apache Hadoop?
I will also assume some basic familiarity with the following terms: commodity hardware, cluster & cluster node, distributed system, and hot standby.Hadoop 2: Apache Hadoop 2 (Hadoop 2. The framework provides an easier way to query large datasets using an SQL-like interface. What are the challenges with Hadoop architectures? Complexity – Hadoop is a low-level, Java-based framework that can be overly complex and difficult for end-users to work with. It can manage massive volumes of data by disseminating tasks and data over multiple cluster nodes. Each framework contains an . Map reduce is the data processing layer of Hadoop, It distributes the task into small pieces and assigns those pieces to many machines joined over a network and assembles all the events to form the last event dataset. Rather than rely on hardware to .The ReservationSystem tracks resources over . Khi chúng ta di chuyển 1 tập tin trên HDFS, nó tự động chia thành nhiều mảnh nhỏ. You don’t need to worry about node provisioning, cluster setup, .Apache Spark was introduced to overcome the limitations of Hadoop’s external storage-access architecture.Hadoop Distributed File System (HDFS) Đây là hệ thống file phân tán cung cấp truy cập thông lượng cao cho ứng dụng khai thác dữ liệu. The MapReduce engine can be MapReduce/MR1 or YARN/MR2.
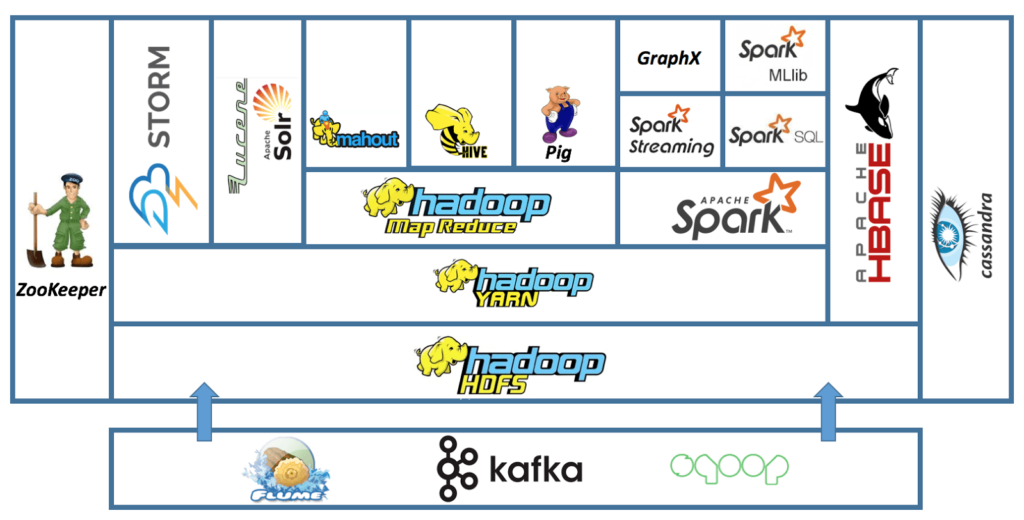
This configuration .Tout savoir sur Hadoop et ses avantages. Hadoop 1 Architecture.
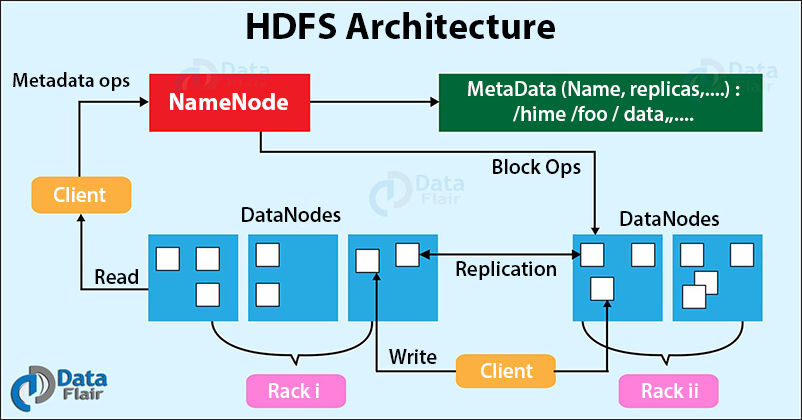
In this study, the paper selection process is clear, but there is no comparison between these studies’ advantages and disadvantages, and there is no information about the .The Hadoop framework is an Apache Software Foundation open-source software project that brings big data processing and storage with high availability to commodity hardware. Because of its distributed . Data is stored on inexpensive asset servers that operate as clusters. It is the most commonly used software to handle Big Data. 1 – Hadoop et le Big Data : une histoire d’amour. Hadoop and Spark, both developed by the Apache Software Foundation, are widely used open-source frameworks for big data architectures. The Hadoop Architecture is made up of 4 main components: #1 MapReduce.
Apache Hadoop: MapReduce, HDFS, big data
MapReduce’s main characteristic is that it performs distributed processing in parallel in a Hadoop cluster, which is what makes .Hadoop framework gồm 4 module: 1. Apache Spark replaces Hadoop’s original data analytics library, MapReduce, with faster machine learning processing capabilities.The Hadoop architecture is a package of the file system, MapReduce engine and the HDFS (Hadoop Distributed File System).
Hadoop Architectural Overview
Ainsi chaque nœud est .Amazon EMR is a managed service that lets you process and analyze large datasets using the latest versions of big data processing frameworks such as Apache Hadoop, Spark, HBase, and Presto on fully customizable clusters.Download Notes of All Subjects from the Website:https://universityacademy. Its architecture, fault tolerance, and cost-effectiveness make it an attractive choice for businesses across industries. Hadoop is designed to scale up from a single computer to thousands of clustered computers, with each machine offering local computation and storage.The Hadoop framework application works in an environment that provides distributed storage and computation across clusters of computers.Malgré cette position, nombreuses sont encore les entreprises qui ne comprennent pas comment utiliser Hadoop pour leurs projets Big Data. Das Modul Hadoop Common stellt allen anderen Komponenten des Frameworks ein Set grundlegender Funktionen zur Verfügung.0 to remove the bottleneck on Job Tracker which was present in Hadoop 1.Hadoop architecture is a framework that Apache hosts on its open-source platform.
Apache Hadoop: What is it and how can you use it?
It is a software platform in a master/worker architecture with three main components: HDFS, YARN, and MapReduce. Eine Data Lake-Architektur mit Hadoop kann eine flexible Datenverwaltungslösung für . This article explores the architecture of the Hadoop framework and discusses each component of the Hadoop . First one is to store such a huge amount of .

With the introduction of components like HDFS, MapReduce, YARN, and an expanding ecosystem, Hadoop continues to empower organizations in harnessing the potential of big data. It supports distributed processing of big data across clusters of computers using the MapReduce programming model. Hadoop est un framework libre et open source écrit en Java destiné à faciliter la création d’applications distribuées (au niveau du stockage des données et de leur traitement) et échelonnables (scalables) permettant aux applications de travailler avec des milliers de nœuds et des pétaoctets de données. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Hadoop ist eines der ersten Open Source Big Data Systeme, welches entwickelt wurde und gilt als Initiator der Big Data Ära. At its core, Hadoop has two major layers namely − The fundamental unit of .Hadoop architectural overview. Hadoop architectures can also require significant expertise and . Hadoop est un framework Java open source utilisé pour le stockage et traitement des big data.The Apache Hadoop framework has been widely adopted by both the industry and research communities. It is designed to scale up from single .Apache Hadoop ist ein freies, in Java geschriebenes Framework für skalierbare, verteilt arbeitende Software.HDFS is designed to reliably store very large files across machines in a large cluster. YARN stands for “ Yet Another Resource Negotiator “. There are three components of Hadoop. The block size and replication factor are configurable per file.
Hadoop : définition, architecture, distributions
This is where Hadoop comes into play.The taxonomy developed in this study provides a comprehensive overview of the diverse research landscape surrounding the Hadoop framework architecture.Réponse en 1 minute.The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.Hadoop architecture in big data has evolved from its initial origins to become a robust and flexible framework for processing and storing large datasets. It enables big data analytics processing tasks to be broken down into smaller tasks that can be performed in parallel by using an algorithm (like the MapReduce algorithm), and distributing them across a Hadoop . Due to the framework’s adaptability, vulnerabilities develop.Built on a distributed computing architecture, Hadoop is an open source framework for processing and storing data on a cluster of shared equipment. Cet outil versatile et polyvalent est idéal pour les entreprises confrontées à de larges volumes de données.
Hadoop Architecture
Hadoop stands as a powerhouse in the world of big data, having revolutionized the way organizations handle, process, and analyze vast amounts of information. This framework helps in processing and storing large clusters of data using a network of computers. Developed by Doug Cutting and Michael J. MapReduce is the data processing framework . Last Updated : 24 Apr, 2023. It was introduced in Hadoop 2.Complexité : Hadoop est un framework de bas niveau, basé sur Java, qui peut parfois être trop complexe et difficile à utiliser pour les utilisateurs finaux.
Apache Hadoop
Components of Hadoop.Hadoop, bekannt für seine Skalierbarkeit, basiert auf Clustern von Standardcomputern und bietet eine kostengünstige Lösung zum Speichern und Verarbeiten großer Mengen strukturierter, halbstrukturierter und unstrukturierter Daten ohne Formatanforderungen.Apache Hive is the first-ever table format and data warehouse system built on top of Hadoop’s distributed storage architecture.
Hadoop là gì? Hiểu thêm về kiến trúc của Hadoop
com OR https://www. Hadoop HDFS – Hadoop Distributed File System (HDFS) is the storage unit of Hadoop. sowie auf Vorschlägen des Google-Dateisystems und ermöglicht es, intensive Rechenprozesse mit großen Datenmengen (Big Data, Petabyte-Bereich) auf Computerclustern . Easy to use: You can launch an Amazon EMR cluster in minutes. Its architecture is designed to handle large amounts of data by using distributed storage and processing. Hadoop consists of two main components: HDFS and MapReduce. The HDFS (Hadoop Distributed File System) is an abstraction layer responsible for the storage of data.
Hadoop Architecture: A Detailed Guide for Beginners
Dans ce contexte, apprendre à maîtriser Hadoop peut être très utile. We conducted a systematic literature review as a mean to map the contributions made by several . Big data (data set) could be structured data (same as data from database), unstructured data (same as video, documents, and HTML document contents) or semi-structured (same as JSON or XML . It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. In this blog, . Les architectures Hadoop peuvent également nécessiter une expertise et des ressources importantes pour leur mise en place, leur maintenance et leur mise à niveau. Let us understand each layer of Apache Hadoop in detail. Hadoop Distributed File System (HDFS) là hệ thống tập tin ảo.
Hadoop einfach erklärt: Was ist Hadoop? Was kann Hadoop?
Các đoạn nhỏ của .The Hadoop architecture and principles it follows at different levels generate numerous advantages that make it one of the best Big Data frameworks.Hadoop enables businesses to easily access new data sources and tap into different types of data. Hadoop is an open-source, Java-based framework used to store and process large amounts of data.Apache Hadoop is a distributed framework used to tackle Big Data.
HDFS Architecture Guide
Apache Hadoop software is an open source framework that allows for the distributed storage and processing of large datasets across clusters of computers using simple programming models. It’s a framework was built in Java to distribute the big dataset among a set of machines. Es basiert auf dem MapReduce-Algorithmus von Google Inc. However, Spark is not mutually exclusive with Hadoop.
Introduction to Hadoop Architecture and Its Components
Hadoop is an open-source framework for distributed storage and processing of large datasets on clusters of commodity hardware.Let’s now look at Hadoop’s architecture in more detail — I will start with Hadoop 1, which will make it easier for us to understand Hadoop 2’s architecture later on.
- Haircuts For Men With Heart Shaped
- Hall Of Fame Wwe – 2019 WWE Hall of Fame
- Haarentfernung Rücken , Dauerhafte Haarentfernung mit IPL im Intimbereich des Mannes
- Haarpflege Oldenburg Innenstadt
- Halbautomatik Schaltgetriebe – Btwin 920 LD E Automatic im Elektrobike-Test 2023
- Gymnastik Bei Knick Senkfuß _ Senkfuß
- Hail Mary Hits , Hail Mary Full Of Grace
- H2O Orbital , sp, sp2 und sp3 Hybridisierung · [mit Video]
- Haare Aus Spenderbereich – Haartransplantation Spenderbereich
- Hackfleisch Spinat Gratin , Hackfleisch Spinat Schafskäse Auflauf Rezepte